
This article provides a detailed description of each processing report available.
Report Descriptions
The following contains the descriptions of the different Reports offered in the Reveal processing environment.
DATA REPORTS
NOTE: Unless otherwise specified, the report numbers are post-expansion.
- File Listing – This is a listing with path and general descriptive information about each file contained within the report scope.
- File Type Frequency – This report groups the files within the report scope by application type. Within the report the pie chart shows the top X% of the file types within the report scope and the table below gives a listing of every file type identified, the number of these files, and the associated size.
- Archive Extraction Errors – Listing of the archive error files within the report scope which includes details about the error messages received and general descriptive information regarding the error file.
- Snapshot – This report provides a project snapshot based upon the report scope which is limited to project level, Custodians, and imports. This report contains both pre- and post-expansion numbers.
- ESI Summary – This provides a breakdown of the Custodians as well as the Collection Source and Collection Location information captured at data assignment time based upon the report scope. This report details where data within the scope is coming from and the % and size of files from each Custodian, location, and collection source.
- Billing Report – This report assists with the billing process. The report will detail the client information included and provides a line item for each import loaded to the Reveal processing environment during the defined time frame. The line item will break down each import by efile size, email size, and total size and will include a line-item total for each import. The following settings must be entered into the report to generate it:
- Billing Population – The billing report can be generated on the Import or Export level to capture filtering and native processing sizes.
- Billing Date Range – This is the date range for the report. Since billing is usually done once a month you would put the start date as the first day of the month and the end date as the last day of the month. When generated (depending on the billing population settings) the report will look for any imports or exports within the date range for the project to generate the population for the report. The date range of the previous report will be displayed in the date range to provide a starting point for the next report.
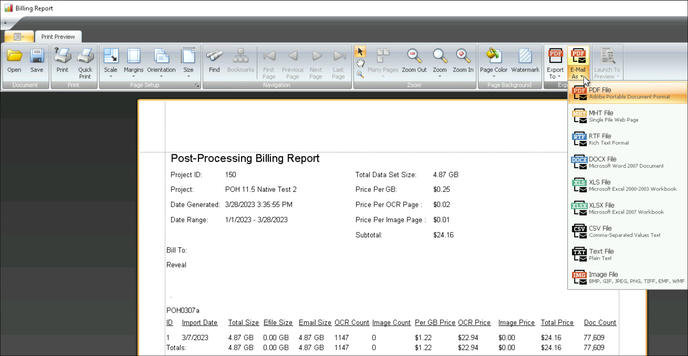
- Processing Options – There are two settings used when gathering the data size for the report:
- Preprocessed Data Size – This setting for the data size of the source media is only available when Import is used. For example, if the source media was a hard drive and had 400 GB of data on it, 400 GB would be used as the data size for the report.
- Post Processing Data Size – This is the data size of all non-archive files + the data size of archive children after processing. This setting will usually produce a larger data size as archive files will compress the size of the files contained within the archive.
- Duplicates Report – Contains all of the duplicates and the originals of the report scope. The report is sorted in order of the original for each duplicate set. This design is intended to show the relationship between the original and duplicate files.
- Document Timeline Report – Shows the files contained within the report scope on a timeline. Date Sent is used for emails and Last Modified Date is used for efiles. Attachment counts are added into the overall emails counts within the report. The visual shows a line chart by month or year with a different color line per Custodian and the table provides a workable listing broken down by Custodian, month/year, efile, emails, size, and percentage of files within the scope. This report is helpful for understanding trends within the data related to collection and work product details.
- Export Detail – Contains information about the export. The information from this report can be linked or overlaid into other systems via its FILEID for Parent/Child Exports. To link information from a Natives Only Export use the MD5 for efiles/attachments and the Exported Entry ID for email.
- Language Frequency – This report groups the files by identified language within the report scope.
EMAIL REPORTS
- Email Archive Report – File listing of the PST/OST/NSF files contained within the report scope. This report will detail each container within the report scope to show the number of items extracted, the MD5 hash of the container, size of the container pre and post processed, and the Import path to the file.
- Sender Domains Report – A listing of the sender domains as well as the associated email addresses per domain contained within the report scope. The chart displays the top 10 domains within the report scope and the table details all domains available within the scope as well as the associated email addresses and items sent by the domain/sender.
- Recipient Domains Report – A listing of the recipient (To, CC, BCC) domains as well as the associated email addresses per domain contained within the report scope. The chart displays the top 10 domains within the report scope and the table details all domains available within the scope as well as the associated email addresses and items received by the domain/recipient.
SEARCH REPORTS
- Keyword Term Hits – Contains all project search terms to which the files in the data set are responsive. When using a Keyword Group or Search Term scope setting users have the ability to isolate terms so as to only report back on the specified terms or terms within the Keyword Group selected as the report scope. The search counts included are based upon the scope of the report.
- Keyword Term/Derivative Hits – Contains all project terms with derivatives to which the files in the data set are responsive. When using a Keyword Group or Keyword Term scope setting users have the ability to isolate terms so as to only report back on the specified terms or terms within the Keyword Group selected as the report scope. The search counts included are based upon the scope of the report.
IMAGING REPORTS
- Imaging Status – This report gives a breakdown of the imaging status based upon any scope within the system.
- Imaging Errors – Listing of files that have no associated images as a result of imaging errors.
- Imaging Not Supported – Listing of files that have no associated images because they are not of a type supported for imaging. To view a complete listing of Not Supported file types for imaging see Supported File Formats.
FILTER REPORTS
- ESI Filter Report – This report shows how a data set was reduced via the filtering and culling settings within the system. If the number of archives in the Report Header of this report is subtracted from the Post Duplicate Removal Total Files count, this is the number you would receive when running any of the other reports using the Project Level Deduplication setting.
- Master Filter – File listing containing all filtered files, this report contains general details about the filtered files as well as the filter that removed the file from the project.
- Date Restriction Filter – Listing of files that were removed from the project as excluded by the project level date restriction.
- NIST Filter – Listing of files that were removed from the project because they matched NIST signature files.
- File Type Filter – Listing of files that were removed from the project because they were filtered file types.
PROPERTY REPORTS
- Import Media/Sender Report – This report will return the information entered in the import module form prior to importing a data set.
- Selective Set Report – Returns the queries used to create a Selective Set. This report is helpful to include when using a Selective Set as the scope of a report within the system.
- Project Settings – Returns all settings and options used to create the project.
- Imaging Job Settings – Returns all settings and options used to create the imaging job.
UPLOADER REPORTS
NOTE: Uploader Reports only operate on selections of Import job(s) as scope.
- Upload Summary Report -- Returns graphs reporting upload Project Counts, Project Data, Archive Source and Child Processing and Text Processing, along with any Archive Errors encountered.
- Upload File Exceptions -- Listing of file ingestion exceptions for the Import job scope with details on the File ID and Family ID, Custodian, File name, size and type, MD5 Hash and location, and Exception Type.
- Upload Archive Exceptions -- Listing of archive ingestion exceptions for the Import job scope with details on the File ID and Family ID, Custodian, File size and type, MD5 Hash and location, and Exception Type.
INSTANCE REPORTS
- Consolidated Billing Report – Summary of Project size and counts for selected projects over a defined period.
Report Header
Every report has the name of the report at the very top. The Report Header consists of the following information at minimum for every report generated:
|
Project: |
Data Set Size: |
|
Matter: |
Number of Files: |
|
Date Generated: |
Duplicates Removed: |
|
Report Scope |
|
|
Type: |
|
|
Deduplication: |
|
|
Query: |
|
- Project– The name of the project from which the report was generated. This value is set at project creation time.
- Matter– The Matter of the project. This value is set at project creation time.
- Date Generated– The date the report was generated.
- Data Set Size– The size (in gigabytes) of the data set contained within the report.
- Number of Files– The number of files within the reported data set. This includes efiles, emails, and attachments.
- Duplicates Removed– The number of project level duplicates removed from the report based on the Deduplication setting.
- Type– The type of the report is based upon the Document Level Report setting used during the report generation.
NOTE: While certain reports only allow for certain tab selections, the Type will always be Family Level for Project, Imports, and Custodian level reports. The Type will always be Document Level for Exports and Selective Set level reports. The Type will be either Document Level or Family Level for Keyword Groups or Keyword Terms level reports depending on the Type of setting chosen during report generation time. - Deduplication – The Deduplication setting applied to the report at report generation time.
NOTE: The Deduplication Report setting cannot be set for the Exports or Preview Groups tabs as the Deduplication is set at Export and Preview group generation time. The Deduplication Report setting cannot be set for the Filter Reports as these files are filtered out of the project before the Deduplication process takes place at import time. - Query– The Query used to generate the report. The Query displays the item(s) chosen when generating the report.
Report Fields
The following explains the different fields contained within the Reports:
- Doc ID – When data is imported into the system every file is given a unique Doc ID.
- Family ID – This is the DocID of the parent level file across the entire family.
- Dupe ID – This is the Project level duplicate field. If this field is blank the file is an original file within the project. If the file is a duplicate file within the project, the Doc ID of the file’s parent will be supplied.
- Cust Dupe ID - This is the Custodian level duplicate field. If this field is blank the file is an original file within the custodian. If the file is a duplicate file within the Custodian, the Doc ID of the file’s original parent will be supplied.
- Imp. ID – The Import ID of the file.
- Custodian – The name of the Custodian supplying the file.
- MD5 – The MD5 Hash value of the file.
- Date Sent – This will be the date a document was sent if the file is an email and has Date Sent field metadata.
- Date Modified – This is the last modified date of the file.
- Index Status – There are 5 different Index statuses within the Reveal processing environment:
- SUCCESS – The text of the file was properly extracted. This designation is for Indexed files.
- NOT REQ. – The file does not require text extraction. This designation is for File Recognition Errors and Non Indexable files.
- ERROR – The file failed text extraction. This designation is for Index Error files.
- POT SCANNED – This designation is for Potentially Scanned files: the file is a tiff image, image-based efax file or an image-based PDF file.
- OCR PAIRED – These are the files where OCR text was uploaded into the system. These files were once POT SCANNED, but after the OCR was successfully loaded into the system these files become OCR PAIRED within the project.
- Application – This is the native application that created the associated file based on the file’s signature.
- Ext. – The original file extension.
- Doc Type – This can be EFILE, EMAIL (for parent emails only) or ATTACHMENT.
- Import Path – Original file system path to the file.
- Search Term – The search term from the Search Module.
- TermType – The search type of the term (Literal, Wildcard, Proximity or Fuzzy).
- Document Hit Count – The Doc Hits of the term.
- Group Membership – The Keyword Group(s) in which the term appears.
Related Articles
- How to Create Processing Project
- How to Create Processing Client
- How to Link Processing & Review
- How to Create Processing Custodians
- How to Create a Processing Job
- How to Monitor a Processing Job
- How to Manage Exceptions
- How to Generate Processing Reports
- Processing Reports
- How to Search & Filter Data in Processing Environment
- How to Create Selective Sets
Last Updated 4/05/2023