
This article provides an overview of Reveal's Supervised Learning feature set.
Introduction
Supervised learning, also known as supervised machine learning, is a subcategory of machine learning and artificial intelligence. It is the process of using manually coded document examples to train Classifiers (algorithms) to automatically classify data or predict whether a document is relevant, privileged, etc.
Supervised learning's training process uses classifier algorithms to generate predictive scores as to the subject matter of the classifier. Classifiers may be binary (Positive / Negative or Relevant / Not Relevant) based on reviewer application of mutually exclusive AI tags, or may categorize data by issues defined in a multi-select AI tag. This training results in the creation of an AI Model which may be saved to an AI Model Library and reused in similar matters.
Process
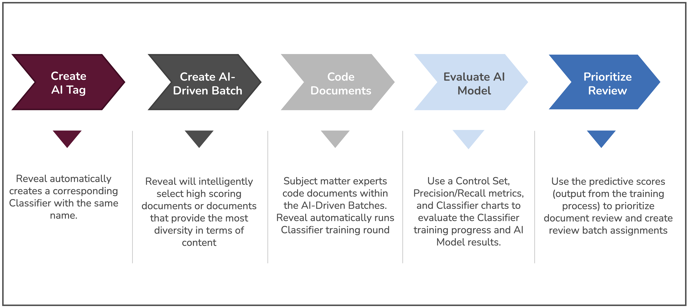
The process begins with creating an AI Tag in Reveal. When you create an AI Tag, the system automatically creates a corresponding Classifier. A Classifier is a representation of the AI Model during the training process. As you code documents with your AI Tag, those coding decisions are used to train the Classifier. After a training completes, the Classifier's AI Model will generate Predictive Scores for each document.
Here is a graphical representation of the Supervised Learning workflow.
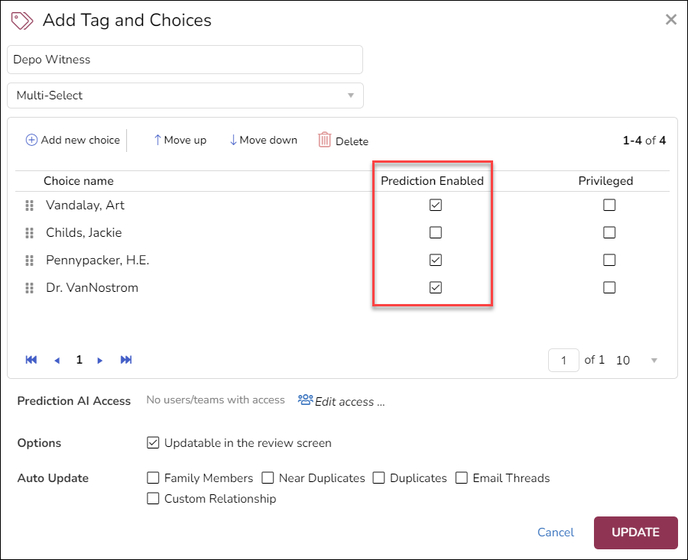
Before creating a classifier, you must first create a tag in Reveal and flag it as Prediction Enabled. (See How to Create & Manage Tags for details on how to do this.) Typically, the tag would be a mutually exclusive type and its choices would be Positive / Negative or Responsive / Non-Responsive. You can add additional choices to the tag that will appear as radio buttons for use in Reveal, for example Further Review Required or Tech Issue, but these will not be used in AI classification.
This type of classifier is typically applied identifying relevant data in the project, and may also be used to implement one of two review strategies:
- Prioritized Review to push documents automatically classified through rounds of training as relevant to be reviewed first. This strategy seeks to expedite assignment of documents scored as probably relevant.
- Recommended Coding Review goes one step further in applying classifier coding decisions to unreviewed documents. This use case is often applied to the production of documents to a requesting third party. The establishment and application of target metrics for coding decisions, as reported under View Classification, is used to compare and validate these decisions against benchmarks established by subject matter experts.
Another type of tag that may be used in creating a classifier is a multi-select type that offers a checkbox for each choice so that one or many may be selected. This might be used to classify issues that appear in documents under review. Here Reveal will create a classifier for each choice under the tag that is flagged as Prediction Enabled.
Once the connected AI tag is created click Supervised Learning to open the Classifiers screen.
View and Edit Classifier
.png?quality=high&width=688&height=298&name=35%20-%2001%20-%20Classifiers%20Screen%20(Cards).png)
The Classifiers screen will display all Classifier models currently associated with the Project on cards, with current status and the option to view or edit their details or create a new Classifier. New Classifiers will display PRE-TRAINING for Rounds, with initial PRE-TRAINING data displayed.
Classifier cards provide a summary of the model's status:
- Name: The short name of the classifier; should label its intended function.
- Training method: Whether the model is set for Active Learning (ongoing assessment and automatic update) or Supervised Learning (user-provided training by tagging).
- Rounds: How many sets of documents have been provided for evaluation so far, or PRE-TRAINING for new classifiers.
- Progress: How many of the provided documents have been coded.
- Status: The model's state of readiness for use; glide the pointer over the (?) information mark for more detail.
- For PRE-TRAINING classifiers initial Positive and Negative data will be displayed.
As of Reveal’s February 2024 release, the classifier screen may also be shown in List view. Clicking the classifier name opens the View Details screen, and the Edit Classifier button is at the right of the row. Note too the addition of a Composition field explaining the mode of batching used and its effect on the training of the classifier.
.png?quality=high&width=688&height=286&name=35%20-%2002%20-%20Classifiers%20Screen%20(List).png)
As noted above, embedded in the Classifier Name is a link to View Details. Within this screen is a Classifier navigation panel that currently has two sections, PROGRESS (for the status of the classifier’s training) and MODEL INSIGHTS (for reports on features underlying Reveal’s analytics). PROGRESS has two entries, Tagging & Scoring and Control Set.
View Classifier – Tagging & Scoring
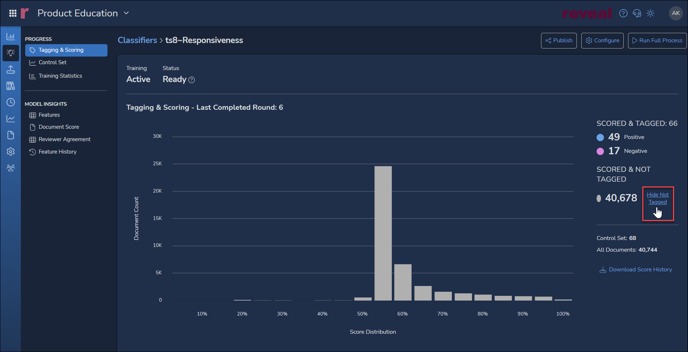 The details screen shows the results and status of training as discussed in the card summary above, including:
The details screen shows the results and status of training as discussed in the card summary above, including:
- Training type
- Status
- Number of Documents Tagged
- Number Positive
- Number Negative
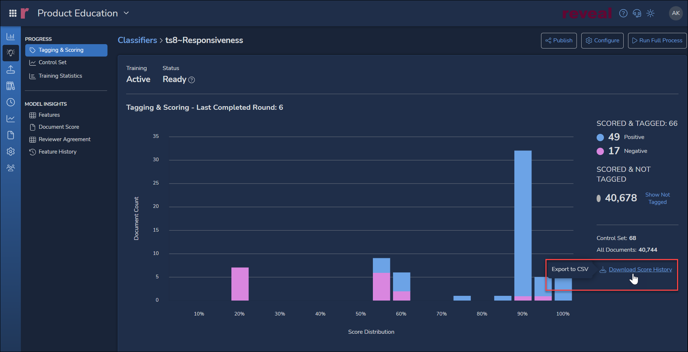
The chart above shows the predicted score distribution for documents not yet tagged when the details screen is first opened. Toggling Hide Not Tagged, the chart below will display Tagging & Scoring across the project showing documents as coded (e.g., Positive / Negative for Responsiveness) graphed against the AI model's prediction of Responsiveness relevance. See How to Evaluate a Classifier for further details on this and the following classifier reports.
View Classifier – Control Set
Control Sets are used to establish target metrics for the classifier. These benchmarks set on sample data by subject matter experts, allow review managers to compare and validate classifier predictive scores. The standard metrics are:
- Precision – the percentage of machine scored documents that are in agreement with reviewer tagging.
- Recall – the quality comparison of predicted versus manual retrieval of positive documents.
- F1 – the harmonic mean of Precision and Recall.
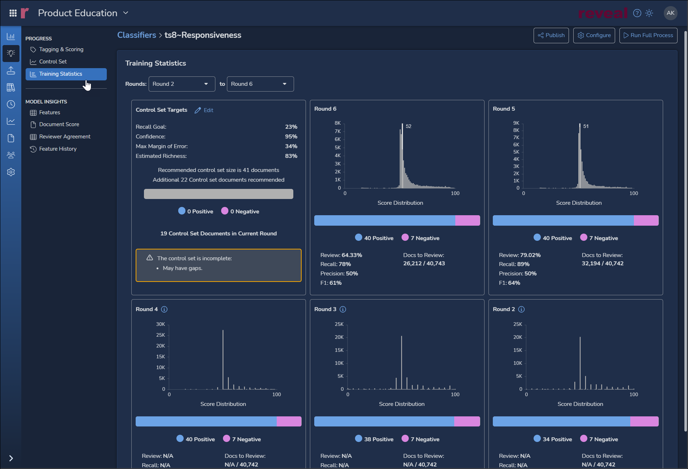
View Classifier – Training Statistics
A graphical and numeric report on each training round as compared with editable Control Set targets is found under the Training Statistics screen added as of the Reveal 2024 February release.
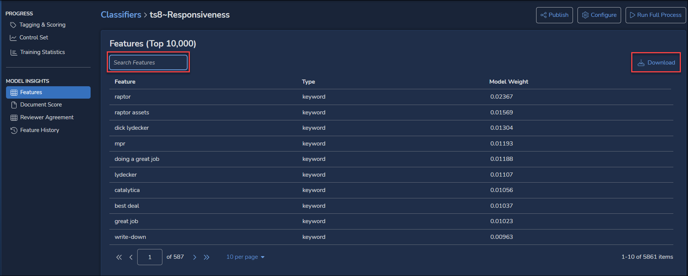
View Classifier – Model Insights - Features
Features reports keywords, entities and other values that have contributed to the current classifier’s model and the weight accorded each feature.
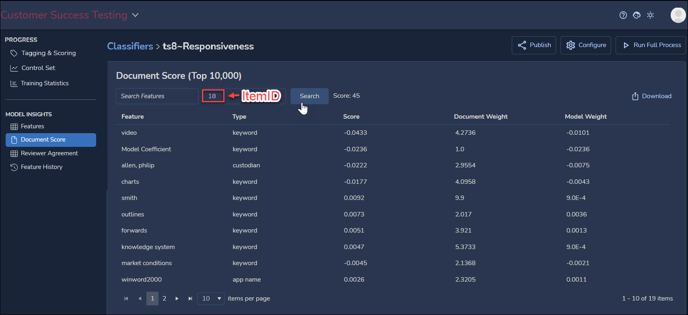
View Classifier – Model Insights – Document Score
Document Score applies MODEL INSIGHTS to an individual document selected using its ItemID control number.
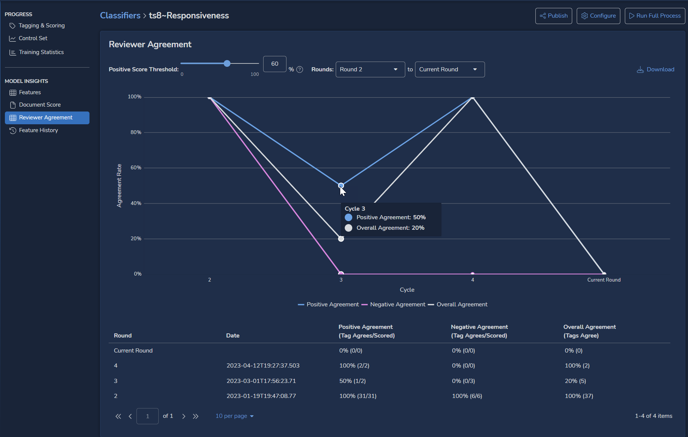
View Classifier – Model Insights – Reviewer Agreement
Reviewer Agreement shows for each training round how often classifier and human reviewers agreed. Positive, Negative and Overall agreement rates are charted as percentages for each cycle. The Positive Score Threshold may be set higher than the 60% shown in the illustration below, and a later round may be selected as a starting point.
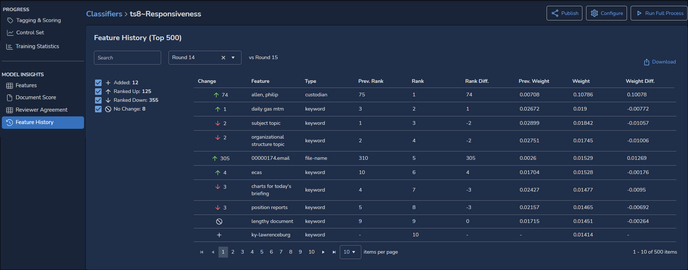
View Classifier – Model Insights – Feature History
Feature History compares the top-ranking 500 features from the latest round with how they ranked in a previous round. The table may be downloaded to CSV format.
Edit Classifier
Clicking the Configure gear icon in the upper right corner of the card opens the Edit Classifier screen, where its configuration may be viewed and updated. See How to Build & Configure a Classifier for details on these settings.
Last Updated 2/23/2024