
This article provides both visual and written instructions for evaluating the performance of a classifier in scoring document content.
An important part of the classifier training process is to assess how the actual coding compares with the model's predictions. This is done in the Supervised Learning > Classifiers screen (shown here in Dark Mode). To examine the status of a current model, start by going to the Supervised Learning screen, then click on View Details on the Classifier card below its title.
- With a project open, select Supervised Learning from the Navigation Pane.
- The Classifiers screen will open, displaying a card for each Classifier in the current project. Each card contains a name, training summary and status, a Settings button and a View Details link embedded in the classifier name.
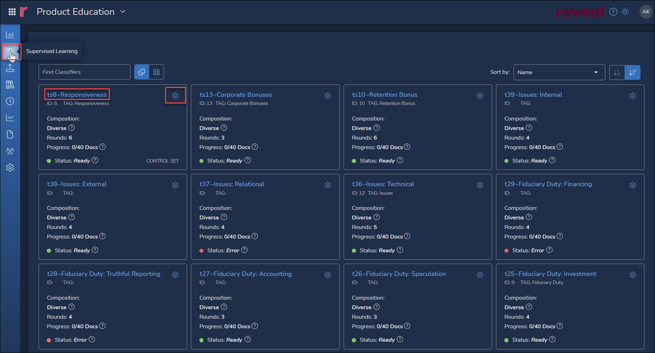
- To examine the status of a current model, click on the Classifier name in either the card or list view. The details window for the selected classifier will open.
The initial view will be of the Tagging & Scoring window, as selected in the left-side Classifier Details navigation pane under PROGRESS. The Not Tagged scores – the AI assessment of likely classifier scoring distribution – opens first. The details screen shows the results and status of training as discussed in the card summary above, including:- Training type – here, Active through AI Tag classification.
- Status – here, Ready for further rounds of training.
- Number of Documents Tagged
- Number Positive
- Number Negative
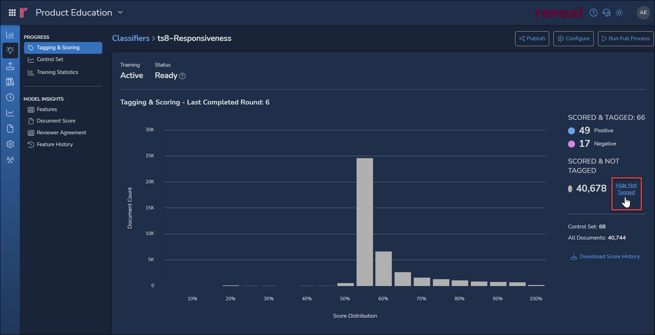
- While the chart above shows the predicted score distribution for documents not yet tagged, toggling Hide Not Tagged will change the chart to display Tagging & Scoring across the project showing documents as coded (e.g., Positive / Negative for Responsiveness) graphed against the AI model's prediction of Responsiveness relevance. Further details for the entire project are broken out at right of the chart. Where the graph shows the bulk of scoring in the uncertain middle of the Score Distribution scale, the classifier is still learning to differentiate between positive and negative scored documents; further training is indicated. To see tagging activity, click Hide Not Tagged to the side of the bar graph.
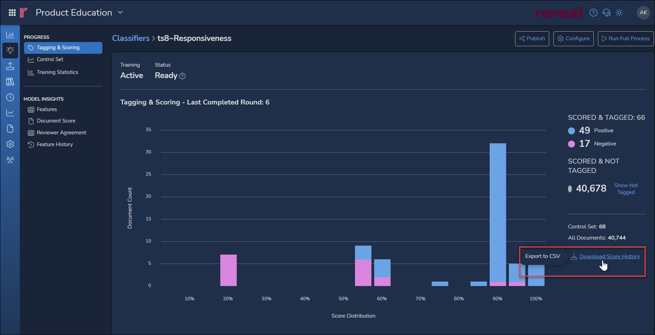
- The above image shows a graph of Tagging & Scoring results. This graph shows actual tagging for this classifier, broken out as document counts of Positive and Negative reviewer assessments of Responsiveness as compared with the related AI Model's assessment of likely responsiveness. As of 4 rounds in which 66 documents have been tagged so far, 49 were tagged Positive and 17 Negative. In this way, a project manager can see at a glance how user coding compares with the model's prediction.
NOTE that negative tagging is extremely important in training AI models, in that these help to define document language that fails to address the subject matter of this tag, which is Responsiveness. - Further training will help to stabilize the classifier and reduce the number of Uncertain documents. Reveal will include Uncertain documents in batching to gain a better understanding of the factors involved in scoring for this classifier.
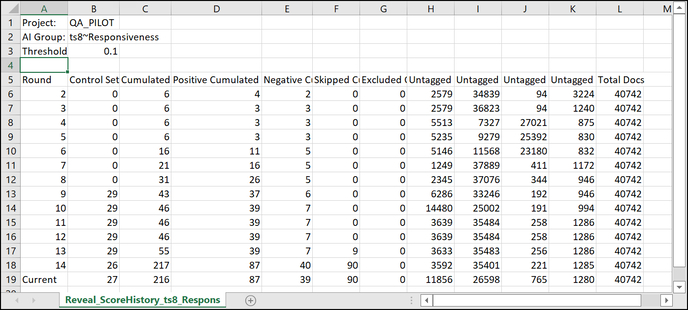
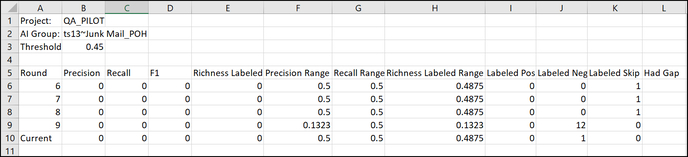
- You may click the link to the right of the graph to Download Score History, which will export the numbers as a table to CSV, as in the example below.
- The next screen available under Classifier Details PROGRESS navigation shows the Control Set activity for the Current Round and for prior rounds. A Control Set is a sample or set of samples coded by subject matter experts, used to weigh and verify the classifier’s analytics.
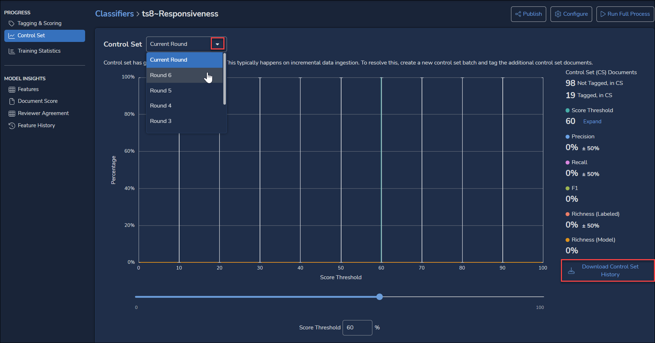
The Control Set chart’s numbers to the right display Precision, Recall, F1 and Richness for the set Score Threshold. The standard metrics are:
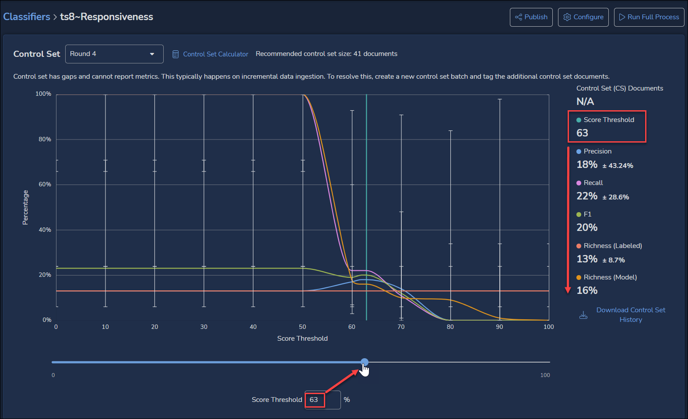
- Precision – The percentage of machine scored documents that are in agreement with reviewer tagging.
- Recall – The quality comparison of predicted versus manual retrieval of positive documents.
- F1 – the harmonic mean of Precision and Recall.- Details for the graph, including Documents to Review, are presented at the right. As the AI model is trained by the classifier, this will display the percentage of documents identified as relevant for accuracy (Precision), inclusiveness (Recall) and quantity of desirable attributes (Richness), which are calculated into a summary score (F1), each with a projected margin of error.
-4.png?quality=high&width=688&height=420&name=31%20-%2005a%20-%20Classifier%20Details%20-%20Control%20Set%20(prior%20round)-4.png)
- The Score Threshold slider below the graph allows the user to set the line between positive and negative scored documents, and to see the number of documents required to achieve a desired level of Precision balanced against Recall. The numeric Score Threshold entered or the slider may be adjusted to a precision of 1% (rather than the 10% bars in the graph); reported values will be updated accordingly.
- At the bottom of the details is a link to Download Control Set History, which will export the numbers as a table to CSV, as in the example below.
- Details for the graph, including Documents to Review, are presented at the right. As the AI model is trained by the classifier, this will display the percentage of documents identified as relevant for accuracy (Precision), inclusiveness (Recall) and quantity of desirable attributes (Richness), which are calculated into a summary score (F1), each with a projected margin of error.
- Training Statistics, introduced in Reveal 2024.2, provides a view of historical score distribution for each closed training round, along with Precision, Recall and F1 scores as may be available reflecting editable Control Set targets. Rounds closed following the Reveal 2024.2 release will have more information than historical rounds closed prior to that release.
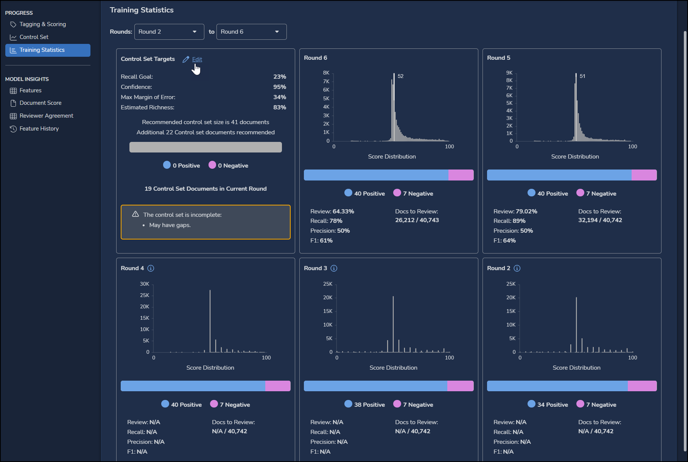
- You may select the range of rounds to be displayed. A very large number of rounds selected may slow the display.
- In the card for each round,
- an X-Y graph will display the score distribution within the round, while
- a bar graph underneath shows the number of positive and number of negative scored documents;
- statistics are presented for:
- Review: Percentage of assigned documents scored.
- Recall: The quality comparison of predicted versus manual retrieval of positive documents.
- Precision: The percentage of machine scored documents that are in agreement with reviewer tagging.
- F1: Blended score for Recall and Precision.
- Docs to Review: Number remaining of the total documents to be reviewed.
- Control Set Targets may be set by clicking Edit in its card at the upper left of the screen.
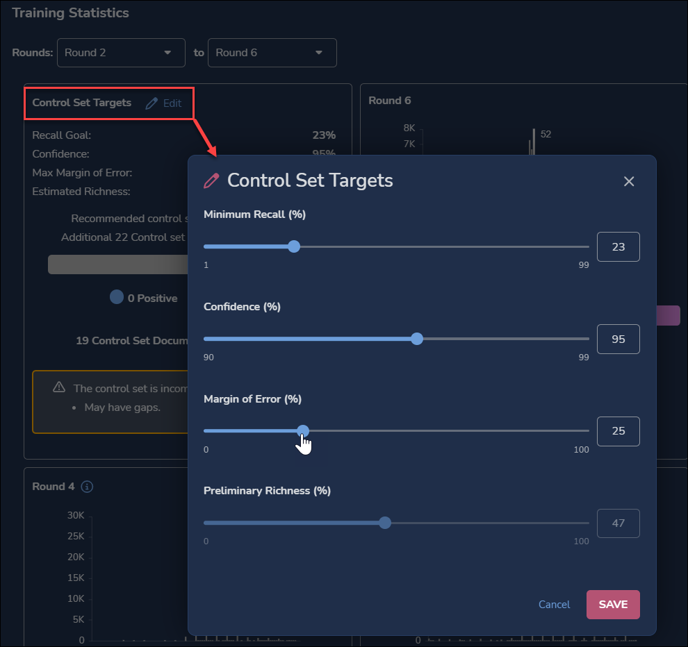
- Based on the Control Set Calculator introduced in Reveal 11.9, this recommends the number of documents needed for a Control Set to address the stated parameters (using the sliders or numeric values) for Minimum Recall, Confidence, Margin of Error, and Preliminary Richness.
- When you SAVE the Control Set Target settings, the card will update a message to recommend a control set size and how many additional documents are needed to address your stated targets.
- You will also be advised whether there are gaps or other issues with the current control set.
- Details on the factors underlying Reveal’s analytics may be viewed under the MODEL INSIGHTS section.
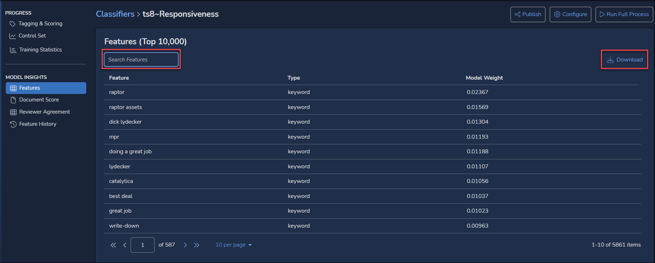
- Features reports keywords, entities and other values that have contributed to the current classifier’s model and the weight accorded each feature. This report can be filtered by Feature name, and may be sorted by any column by clicking on the column heading, toggling ascending or descending; anything other than default descending sort on Model Weight is indicated by a red arrow next to the column heading. You may download a copy of the report as a CSV (subject to checking Run Feature & Score Reports under the classifier’s Advanced Settings), which will not be limited to the 10,000 feature items displayed for performance.
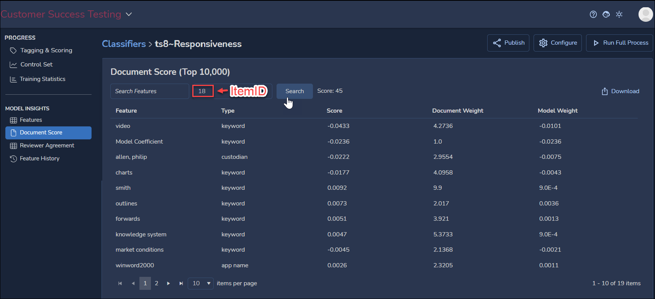
- Document Score applies MODEL INSIGHTS to an individual document selected using its ItemID control number. An overall score for the selected document is shown next to the Search You may search (filter) Features, download a CSV of the report (subject to checking Run Feature & Score Reports under the classifier’s Advanced Settings) that is not restricted to the top 10,000 items displayed for performance, or sort by any column heading, here expanded to include the Score for the feature term and its Document Weight as well as its Model Weight.
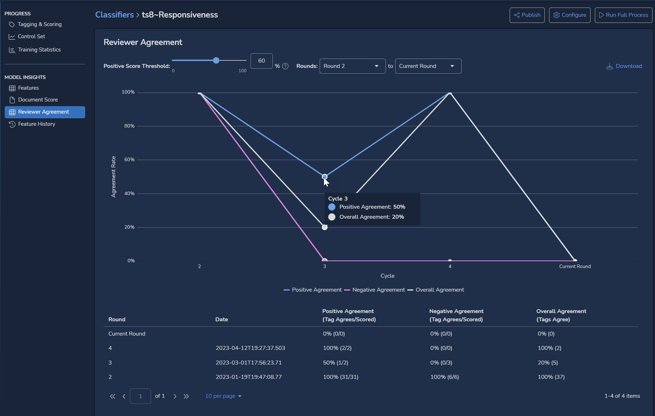
- Reviewer Agreement shows for each training round how often classifier and human reviewers agreed. Positive, Negative and Overall agreement rates are charted as percentages for each cycle. The Positive Score Threshold may be set higher than the 60% shown in the illustration below, and a later round may be selected as a starting point.
- Feature History compares the top-ranking 500 features from the latest round with how they ranked in a previous round. The table may be downloaded to CSV format.
The features are sorted by Rank, with columns showing Change, Type, Previous Rank, Rank Difference, Previous Weight, Weight, and Weight Difference. Several factors are selectable, with a summary count provided for each:
- Added
- Ranked Up
- Ranked Down
- No Change
This allows the user to evaluate how further AI tagging has affected the model’s analysis.
This report will be available only for training rounds closed following upgrade to Reveal 11.8 and moving forward.
To exit the Classifier Details screen, go to the top and click Classifiers in the breadcrumb path.
Elusion Test
Beyond statistical analysis, another way to validate a classifier’s training is to perform an elusion test.
- Under Filters in the Sidebar, expand Document Status and select Has Tags.
- Open search building for an Advanced Search.
- Toggle the Tag Paths: Has Any Value pill to NOT.
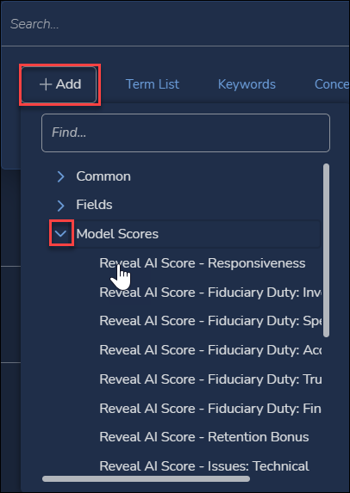
- Click Add.
- Expand Model Scores.
- Select your Responsiveness AI Tag.
- Set the range of scores between zero and your Score Threshold (here, 70).
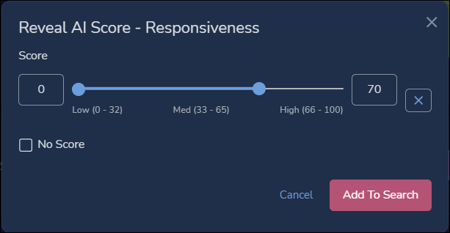
- Click Add To Search.
- Run the Search.
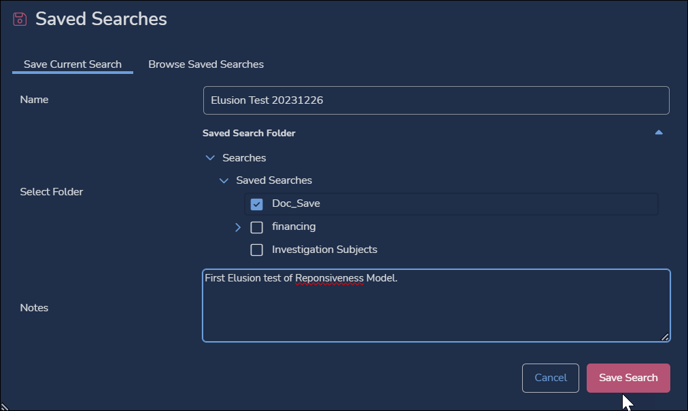
- Save the Search as “Elusion Test” with the current date.
- From the Grid bulk action menu, create a Sample with the following Sample Options settings:
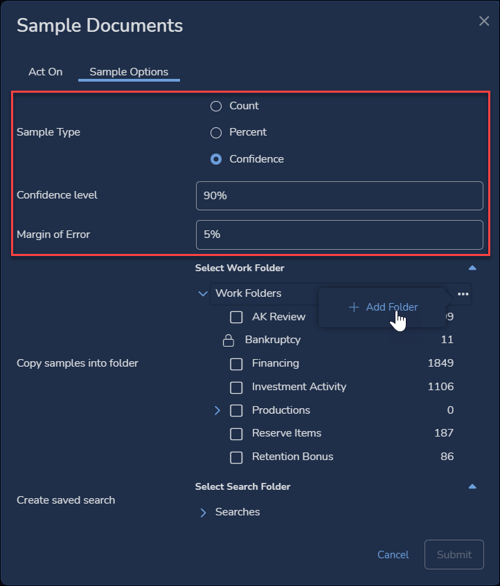
- Sample Type – Confidence
- Confidence level – 90%
- Margin of Error – 5%
- Copy samples into folder – Click on … Options menu to the right of Work Folders and select +Add Folder, providing a name (g., Elusion Test) and permissions.
- Submit.
- Have a subject matter expert reviewer code a 10% sample of the documents for responsiveness, and note the percentage of those manually coded as Responsive in what should have been a non-responsive set. This is your classifier’s current margin of error.
For more information on using Classifiers, see Supervised Learning Overview, How to Build & Configure a Classifier and How to Train a Classifier.
Last Updated 2/19/2024