
This article provides a detailed description of all the features and options associated with detection and labeling of duplicates.
Reveal 11 identifies several categories of document status during the import process, including email threading, duplicate and near-duplicate conditions. This article sets out details about duplicate status analysis, definitions of duplicate status and examples of their application.
Duplicate Detection Methods
Reveal uses two levels of duplicate detection. In decreasing order of strictness, they are:
- Exact Duplicate Detection (EDD)
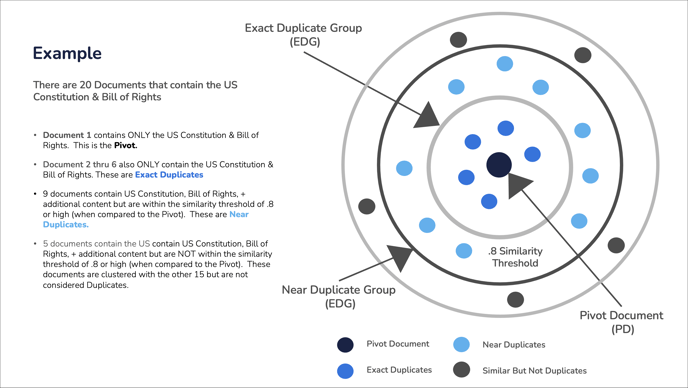
- The Exact Duplicate Detection process uses two components – the duplicate ID exported from Reveal Processing and the body text of the document. If there is no duplicate ID, such as when data is loaded from a third-party load file, the duplicates will be processed using body text. An exact duplicate group (EDG) consists of all documents in a data set that are exact duplicates of a designated pivot document. EDD is done on the file level and is not family dependent.
- Near Duplicate Detection (NDD)
- A near duplicate group (NDG) is a group of documents where each document in the group has high similarity to the pivot document of the NDG, based upon text shingles. Each document is represented as a set of unique shingles, where shingles are the n-grams found in the body text. See the Grouping Messages Into Threads section of Email Threading Overview for a further discussion of shingles and how they are used.
EDD uses MD5 hashing to test for whether two documents are identical. The following characteristics result from the properties of the identity test:
- Equivalence: Any two documents in an EDG are identical not only to the group’s pivot, but also to each other.
- Pivot Independence: The pivot document of an EDG is used as a representative of all documents in the group for some purposes. However, the choice of the pivot document is arbitrary in the sense that the pivot does not determine which documents are in the group.
- Context Independence: If two documents end up in the same EDG when a build is done on any dataset, then those two documents would be in the same EDG in any data set with the same schema.
- Order Independence: EDGs are stable across rebuilds. For a particular schema, a given data set will have the same set of EDG groupings (though not necessarily the same set IDs) regardless of the build history of the data set. For instance, it does not matter whether all data was input in a single build vs. multiple Incremental Analytics with Ingest operations were used on portions of the data.
NDD operates differently from EDD, and is in some ways more similar to clustering than to duplicate detection. The NDD algorithm iteratively selects pivot documents and builds NDGs around those pivots. All documents in an NDG have a minimum level (by default 80%) of similarity to the NDG’s pivot documents, as computed by a shingle-based algorithm (https://www.revealdata.com/knowledgebase/reveal/email-threading-overview#Grouping_Messages_into_Threads). NDD therefore has very different properties than EDD:
- Non-Equivalence: While all documents in an NDG have a specified minimum similarity to the pivot, they may not have that degree of similarity to each other.
- Pivot Dependence: Which documents are chosen as pivots by the NDD algorithm affects which documents are grouped together in NDGs. Thus, anything that affects the choice of pivots will affect the composition of the NDGs.
- Context Dependence: The fact that two documents occur in the same NDG for a given dataset does not mean that they will occur in the same NDG for some other dataset that contains the two documents.
- Order Dependence: Because the choice of pivots affects the composition of NDGs, the order in which documents are added to a dataset affects NDG membership. In particular, inputting all documents in a single build vs. doing multiple Incremental Analytics with Ingest builds may lead to different NDGs.
Roles of Documents within Duplicate Groups
There are four roles that a document can play with respect to any of the three duplicate types. You can find out what role a document plays with respect to each duplicate type by using the fields bd_exact_dup_status and bd_near_dup_status, For every document, each of these fields takes on exactly one of these four values:
- pivot: The document is the pivot member of a group of that type. The pivot of a duplicate group is used to stand in for the whole group in some cases.
- duplicate: The document is a member of a group of that type, but is not the pivot of its group.
- unique: The document was input to duplicate detection, but did not become a member of a duplicate group of that type.
- error: An error occurred on importing of that document, and so it was not considered during duplicate detection.
Group Identifiers
Each duplicate group has an integer identifier called a Set ID. If a document is a member of a duplicate group of a particular type (i.e., has status pivot or duplicate with respect to that type), then the Set ID of the duplicate group it belongs to can be found using the fields bd_near_dup_set_id and bd_exact_dup_set_id. If the document is not a member of a duplicate group of that type (i.e., has status unique or error) then the value of the corresponding Set ID field for that document is null.
Relationship Between NDGs and EDGs
The NDD algorithm is run after the EDD algorithm. It is run only on documents that have bd_exact_dup_status = pivot or unique.
Note the following regarding the relationship between NDGs and EDGs:
- The existence of an EDG containing particular documents does not mean there is any NDG containing any of those documents.
- From the point of view of how an NDG is calculated, when an NDG does contain documents from one or more EDGs, it at most contains the pivots from those EDGs, not the duplicates. This depends on the duplicate type reported for the document:
- Exact duplicates that are not the pivot of an EDG are reported as ExactDup.
- A pivot of an EDG could be reported as ExactOrig, ExactOrigNearOrig or ExactOrigNearDup.
Figure 1 shows the possible relationships between NDGs and EDGs, and the possible values of NDD and EDD status fields for documents input to NDD.
bd_dup_type and the Candy Bar
Reveal 11’s Dashboard includes the Candy Bar visualization that reports the counts for four categories of documents: Originals, Exact Duplicates, Near Duplicates and Not Analyzed. These four categories are further broken down into the eight values found in bd_dup_type.
An example of the Candy Bar:
.png?quality=high&width=688&height=80&name=188%20-%2002%20-%20Candy%20Bar%20(Dark%20Mode).png)
|
Candy Bar: When you click on… |
It returns documents with the following values in bd_dup_type |
|
Originals |
unique |
|
exactorig |
|
|
exactorignearorig |
|
|
nearorig |
|
|
Exact Duplicates |
exactdup |
|
Near Duplicates |
neardup |
|
exactorigneardup |
|
|
Not Analyzed |
excluded |
The dup type field can be considered a description of what was found out about a document during the duplicate detection process. While the EDD and NDD process each have a status field, the dup type combines them for easy analysis.
When considering Exact Dupes, what was discovered about the document?
|
If BD DupType equals… |
Then exact dupe detection found that the… |
Field BD ExactDupStatus equals |
|
unique |
Doc had no exact dupes. |
unique |
|
exactorig |
Doc had exact dupes & became pivot of its EDG. |
pivot |
|
exactorignearorig |
Doc had exact dupes & became pivot of its EDG. |
pivot |
|
nearorig |
Doc had no exact dupes. |
unique |
|
neardup |
Doc had no exact dupes. |
unique |
|
exactorigneardup |
Doc had exact dupes & became pivot of its EDG. |
pivot |
|
exactdup |
Doc had exact dupes & became a duplicate in an EDG. |
duplicate |
|
excluded |
Varies. Document may or may not have been input to EDD. |
any |
Now consider Near Dup detection, what was discovered about the document?
|
If BD DupType equals… |
Then near dupe detection found that the… |
Field BD NearDupStatus equals |
|
unique |
Doc had no near dupes. |
unique |
|
exactorig |
Doc had no near dupes. |
Unique |
|
exactorignearorig |
Doc had near dupes & became pivot of its NDG. |
pivot |
|
nearorig |
Doc had near dupes & became pivot of its NDG. |
Pivot |
|
neardup |
Doc had near dupes & became a duplicate in its NDG. |
duplicate |
|
exactorigneardup |
Doc had near dupes & became a duplicate in its NDG. |
duplicate |
|
exactdup |
Document was not input to NDD. |
Unique |
|
excluded |
Varies. Document may or may not have been input to NDD. |
any |
Last Updated 2/05/2024