


Each week on eDiscoveryLeadersLive, I chat with a leader in eDiscovery or related areas. For the Oct. 16 session, I sat down with Ron Tienzo. Ron is a Senior Consultant at Construction Discovery Experts where he specializes in helping clients use machine learning, artificial intelligence, analytics, and custom workflows to handle complex and large scale construction litigation.
Our discussion focused on AI, challenges with using generalized AI for discovery, and the benefits Ron has experienced using pre-built AI models as well as creating his own custom ones.
Recorded live on October 16, 2020 | Transcription below
George Socha:
Good morning, good afternoon, good evening. Welcome to eDiscovery Leaders Live, sponsored by Reveal and hosted by ACEDS, I am George Socha, Senior Vice President of Brand Awareness at Reveal. Each Friday morning at 11 am Eastern, I host an episode of this program where I get a chance to chat with luminaries in the eDiscovery field and related areas. Today, my guest is Ron Tienzo. Ron is a Senior Consultant at Construction Discovery Experts. He specializes in helping clients use cutting-edge machine learning, AI, advanced analytics, and custom workflows to handle complex and large scale litigation. Music to my ears.
Throughout his career, Ron has provided strategic discovery consulting to mid-sized corporations, as well as to one-third of the Fortune 100 at both the state and Federal levels. Before joining Construction Discovery Experts, Ron was, among other things, Director of Search & Analytics at Catalyst Repository Systems. While he was there, he was instrumental in the development of Catalyst’s Predictive Coding technology. He also worked as a consultant at Legality and as a trainer at the Liner law firm. Ron has a JD from the University Of Denver – Sturm College Of Law. Ron, welcome to today’s session.
Ron Tienzo:
Thank you George, thanks for having me. I’m really excited to be here.
George Socha:
I am glad to have you here for two reasons. One, you’ve got a very specific focus that we’re going to talk about today, construction litigation, which has its own challenges and nuances and I’d like to make sure we cover those. And second, you are pushing the boundaries and the borders of the use of artificial intelligence in litigation, in discovery, and in particular with discovery and construction litigation. Let’s start with the construction industry. What are some of the things that are unique about construction litigation?
Ron Tienzo:
As you had mentioned, before I was doing a lot of class action work, a lot of DOJ second requests – huge data sets with a very small sliver of responsiveness. But now that I’m working in construction, I realize it’s no longer the needle in the haystack. Now, we have these huge multi gigabyte, terabyte construction servers where most of it is responsive or generally responsive, and we end up producing it. What is the role of AI in that when you are dealing with a 90 percent responsive population?
It’s really flipping AI on its head; noticing that, alright I have a barn full of hay stacks, what do I need to cut out?
And then we start using AI to find things like confidentiality or privilege or hot documents, there’s still a lot of use cases even beyond the typical, “I’m going to cull, review, and produce”.
Finding David
George Socha:
That reminds me of the first part of the perhaps apocryphal story about the carving of the statue of David, and chipping away chunks of marble until the statue emerged as if it were always hiding inside there waiting to be…sorry for this…revealed. What are you doing in particular and especially with AI to cut away those chunks?
Ron Tienzo:
To George and everyone out there, George gave me license to bring my own visual aids. I know it’s episode 5 here. So here we go. This is my favorite AI article that came this week: “Onions banned from Facebook for being too sexy”.

And I will tell you, this will relate to your question in just a second. So what happened is, Facebook’s AI engine thought that this image was inappropriate and it was flagged much to the chagrin of the farmer who tried to post it. The problem is that we are relying on AI that wasn’t built specifically for our clients’ needs. This was a generalized AI image recognition engine and it wasn’t used to seeing a bunch of onions. In fact, if it was used to seeing onions, it was more like, you know, “Cover up your onions”.

How does this relate to discovery, construction discovery? We’re seeing a lot of the generalized AI models don’t fit. Being that it’s construction, oftentimes people talk with more crass language than they would in the office, they do in the construction site. For our clients we run a generalized AI engine that’s looking for crass language, overtly sexual content because we want to get that in front of our attorneys before it goes out the door.
We ran this generalized engine and these are the top two hot documents that came up for overtly sexual content:

You’ll notice that it mentions “butt joint” and “pipe nipple”. Now, if this were in a different context, yes you should flag those, but if my AI really understood construction and understood construction terms, it wouldn’t weigh those as heavily. I really think that’s where the evolution of machine learning and eDiscovery is going. We’ve come to the acceptance that AI can help us get to the root of relevant information.
Now, it’s “how can we custom fit AI” so we’re not starting from ground zero or using something that was made for someone else to understand how my clients or how my corporation communicates. That’s what we’re doing with our construction clients, building customized AI that understands the unique nature of construction law and using that to help carve away the marble and reveal the statue of David.
Making AI Better
George Socha:
What’s the customization that makes this possible?
Ron Tienzo:
So, it’s really utilizing your attorney work product. I have another example here.
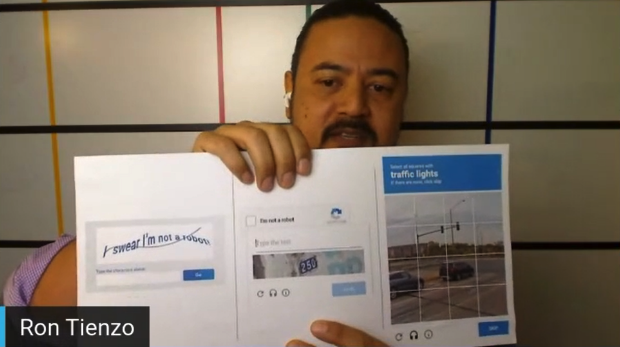
Everybody familiar with these? These are the CAPTCHAs that Google put together. It’s a way for us to prove that we are not artificial intelligence, we’re not robots. What a lot of people don’t know is it started off here, where you had to type the text. And what Google was doing in the background, is they were using this to enhance their OCR engine, because at the time they were OCR-ing a lot of historical documents. But then, Google Maps came out. Then, the capture changed to this, where you start identifying street signs. And then it evolved to this, where now you’re starting to look at traffic lights and other traffic-related items. What they’re doing now is using this human coding to better create AI engines and to test that their AI engines are working effectively, because Google understands that human coding is invaluable and it’s costly and it’s necessary for AI to evolve. So every opportunity Google gets, they’re going to collect that data and try to utilize it to improve their AI engines.
We need to start doing that in e-discovery. So often machine learning has been, “Okay we got our case, let’s turn on our AI engine, start from document one until we reach our stopping point” and then throw that model away. New case comes in, we start at document one until the end, throw that model away. But human coding, especially attorney coding that’s $400, $500 an hour, is invaluable. So, what we’re encouraging our clients to do, is to leverage that information that you gain from that one case and be able to utilize it across multiple cases. Whether it’s issue coding or confidentiality or privilege, there is a common thread throughout how your corporation operates day to day. So we’re trying to leverage that information to make better AI models.
AI Models
George Socha:
Two questions on that. First, just how do you leverage that? And second – we’ll use this as a placeholder and come back – what do you do with anonymization or pseudonymization of that content if that’s necessary? The first, how do you accomplish this?
Ron Tienzo:
Those are both great questions and that really walks the line of AI: where do we factor in privacy as well as the uniqueness and quality control? Those are all aspects that need to be figured out. So, your first question, how do we do it? Well, it’s working with a tool that has a portable model. Meaning, once my case is over, I still have ownership of that model and can apply it somewhere else. Over the course of time, my one case of a hundred thousand decisions becomes 10 cases of a million decisions. That AI model now becomes custom built to understand my corporation or my caseload.
Now, anonymization…. Eventually, I think we can get to a point of anonymization but we’re not there yet, the technology is not there yet. What I have been promoting is within an organization itself. We don’t use the same model for every construction company; we have a client specific model for each.
George Socha:
Do you have then, two layers of models, some that can be used from client to client to client and some, I gather, that are specific just to one client?
Ron Tienzo:
Right now we’re just to one client. So, we use [Reveal AI] and in a lot of our cases, and [Reveal AI] has generalized models that we can enhance.
But again, we’re striking that balance of, “Are we enhancing it with proprietary information from our corporation?”, and then, “What is the possibility of that information getting out?”. For the most part when we are talking about relevance, when we are talking about privilege, we are using core-specific models. If we’re talking about generalized subjects, like “I don’t want ‘butt joint’ to be flagged for every sexually inexplicit model that we have”, then we can use more generalized terms. Really, to break down AI and machine learning, and most the people on this chat know this is, yes it’s complicated, but if we break it down to its core elements we’re really talking about terms and weighted scores. Our ability to export those term lists and those weighted scores allows us to be able to propagate those models to other cases. And really, that’s what we’re trying to extract and utilize for our clients.
Building Bespoke AI Models
George Socha:
How complex is it? You’ve got bespoke models that you’re delivering to specific clients. How complicated is it to build one of those bespoke models?
Ron Tienzo:
I can’t speak for every tool. A lot of it is tool-dependent, on how easy the tool makes it to be portable and who really has ownership of that model once it’s created. Assuming that you’re using a tool that’s flexible, like [Reveal AI], it’s not hard. It’s essentially going through and using that, exporting that model at the end of your review and then applying it again. And let me be transparent here; we’re not talking about a magic bullet. You know, no model is going to be perfect and every case is going to be slightly different, but it’s much better than starting off at ground zero. Every year Amazon doesn’t flush my shopping history so they can build a new model for me, because they know there’s valuable data that’s being accumulated and that’s what we’re trying to leverage.
George Socha:
What is the reaction from the attorneys and support staff you work with at law firms to this approach?
Ron Tienzo:
St has been generally a positive one. For the longest time in this industry, we were fighting the uphill battle of “machine learning can help save you, you don’t have to look at every document”. This has been an easier topic to digest, just because we’re not saying it’s the end all be all, we’re saying that these are tools that are going to help you protect the information that you don’t want released. Miss a few responsive documents or overproduce – that’s part of the business; but when you start actively producing privileged or confidential documents or proprietary information, when you start speaking that language it’s much more palatable to talk about the bespoke machine learning models.
George Socha:
Is the reaction similar or different when it is folks in the house that you’re dealing with and corporate or governmental legal departments?
Ron Tienzo:
It tends to be the same. Just because again, the subject matter. I think that’s a great question. We are not taking work away from anybody.
What we’re really doing is highlighting the most critical content that we’re trying to protect.
And I think everybody wants to do that, whether you’re in the GC’s office or outside counsel or a government agency.
George Socha:
I tend to think of the use of these technologies, the AI technologies and the number of ones around them – machine learning, natural language processing, those various different pieces – as falling into two broad camps. The first are the investigative capabilities and a significant subset of that is “tell me something I don’t know”. The second are the predictive coding, TAR, predictive analytics, whatever you want to call it, capabilities and I think of those as “find more of this”. It sounds as if these models on the approach you’re taking can be used for both sets of approaches, is that right?
Ron Tienzo:
That’s a great point. I’ve been framing this conversation as “as new litigation comes let’s apply this model”, but there’s a lot of investigatory concepts that are involved with this. Let’s say, you are doing an internal investigation or trying to prove a negative, you can build a model that you can operate within your corporate environment to identify these records. Or if you are a retailer, you don’t deal with a lot of huge multijurisdictional cases but you have a lot of human resources matters. Well, build a model that specifically looks for the most relevant documents within your human resources matters, with the idea that the more information I can get, if I know that this case falls into this category and I handled it this way in the past, leveraging that information is going to take so much stress off of your in-house counsel and be able to be far more strategic in how we handle these low-value high-occurrence types of claims.
Costs
George Socha:
So, one last question before I turn it to you for final thoughts. Inevitably, there is going to be a question about cost and whether this is more expensive, less expensive, or equally as expensive as other approaches. What has been your experience?
Ron Tienzo:
This has always been a sticking point in our industry: What is the upfront costs versus the long term cost? Thankfully to say, the upfront cost has already been paid. It was your client’s dollars and cents that went to pay for these attorneys to review them, for the technology to host them, so the model is created from that. What is the associated cost? I would say it’s really minimal; we’re using very similar technology and using information that’s already been gained, we’re just trying to re-leverage it somewhere else. So, not only do we tick the “it’s efficient” box, but we also take the “it’s cost effective” box. That’s my plea to the community: “Hey let’s start doing this, let’s start using AI bigger than the case that’s right in front of us”.
Final Thoughts
George Socha:
Well, that sounds like a great pitch. Final comments and thoughts from you; something I missed, something you’d like to highlight?
Ron Tienzo:
Yeah, I just want to thank everybody for having me here. I do have one last thought and this is more relevant to 2020.

Hey everybody, let’s hang in there, nobody expected this year to be the way it is. Take care of yourself, call your loved ones, make sure they’re doing okay and we’ll all get through this together. So George, I really appreciate the time here.
George Socha:
Ron, thanks very much. My guest this week was Ron Tienzo, Ron is a Senior Consultant at Construction Discovery Experts. Thanks very much Ron.
Ron Tienzo:
Thanks.